
AI-Powered Planning and Design, for Better Project Delivery and Urban Developments
GET STARTEDJOIN Us



Overview
Industries
© 2023 DigitalBlueFoam

Machine Learning (ML) can be powerful in energy efficiency and carbon-friendly designs. However, there is a need for better building data sets to accelerate the use of ML.

Machine Learning (ML) can be a powerful tool to help designers choose more energy efficient and carbon-friendly designs. However, there is a need for better building data-sets to accelerate the use of ML.
ML programs must access vast quantities of data in order to learn. Unlike digital industries, who generate hundreds of billions of megabytes of data daily, most building data is trapped in the physical world. Making matters more complex, the practice of sustainable design is highly localized: the data captured for a building in one particular city, will likely not be useful to compare design options in another.
In this post, I share how Digital Blue Foam is addressing this problem using off the shelf software, and a render farm.

Not always the data available publically will solve your design problem. There was a need to generate the data because as mentioned above sustainability is region-specific. The real-world sensor data would consist of few building performance indicators which can be crucial in building operational phases, also this kind of data would be available only in a few technologically advanced cities. We generated a huge dataset for each city using a parametric model and environmental analysis. This approach is better than the traditional simulation approach, because of the time taken and knowledge required. The ML model would be able to map between different extreme inputs and predict the solutions within seconds. Using cloud computing technology and lots of machines, the data generation process is a lot easier and faster.
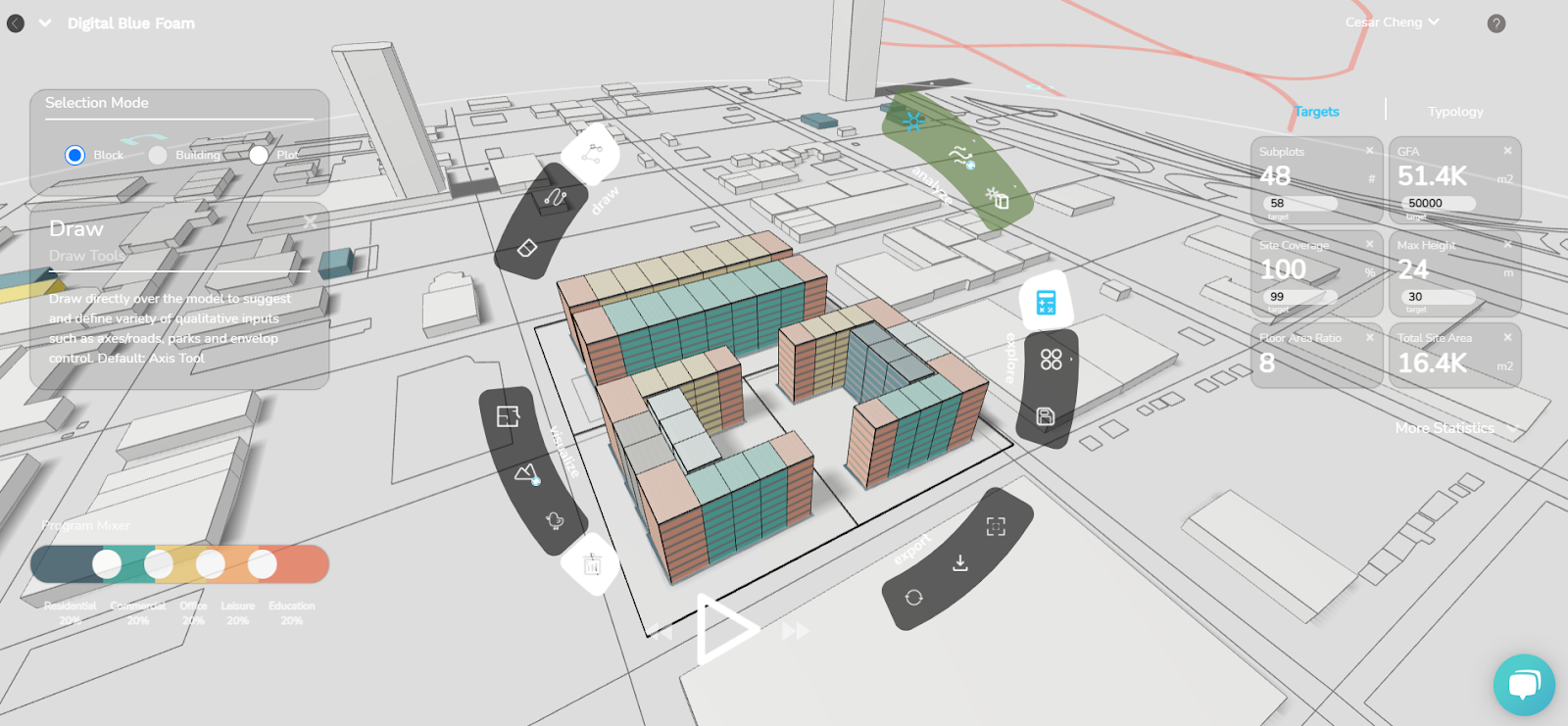
The aim was to build a feature for our users (architects, designers, and urban planners), to measure the sustainability of the design, and compare different options using machine learning.
With the current workflow If an architect or building engineer has to perform environmental analysis for a complex design, it would take at least a couple of minutes and of course good knowledge of Rhino-Grasshopper and its different plugins that support environmental analysis.
Our goal is to compute these sustainability metrics within (milli)seconds so that the users can compare, rate, and rank different design options in minutes.
To generate the simulation data, we chose Grasshopper, because we could create a parametric script and perform environmental analysis, using the Ladybug plugin, together. Once it generated enough structured data, we imported it in python using pandas for further analysis and ML model training. For model training, we used neural networks from the tensorflow-keras library.
This saved pre-trained model was used to create an API, using the google cloud platform, which could be accessed in node js and integrated with other code.
The alternate approach was coding this neural network model entirely in Node js using tensorflow.js library so that we could train and deploy the model in node js itself. But this approach had a small issue, to install the tensorflow.js library into node.js, we needed to upgrade/degrade the version of other packages and libraries, which could affect the ongoing development.
The model could be improved to a certain level by stacking more layers in the Neural Nets, but to significantly improve the performance we needed much more data for a single city, maybe a couple of additional features too.
The above-mentioned approach is a broader view of the process. The main issue was DATA. How to generate so much data?
To generate more data in less time, we needed two things :

We accessed some office desktops and even rented a couple of high computing power desktops. The next step was to set up the entire pipeline of data generation in Rhino-grasshopper. This would be setting up rhino-grasshopper, downloading plugins for the environmental analysis, and setting up folders to store the generated data. Such that the entire process is somewhat automated. But we realized it's very important to monitor this process and manage it across different machines, to avoid any errors, crashes, and duplicate values.
To use GPUs while performing the analysis for each iteration was the most important step, to generate one city’s data in a couple of days. For this we tried a couple of different tools.

Another tool we tried was UMI (Urban Modelling Interface), a Rhino plugin to perform the environmental analysis at an urban scale. It was by far the fastest method to compute the required sustainability metrics and did not even require a GPU-enabled machine. We can even specify certain contextual elements in it, like streets, ground, shading/trees, etc. But creating a parametric grasshopper script is the trickier part here.
The ML model training took less than an hour with Google Colab, but finding the optimal and faster way to generate the data took almost a month.
It is always important to consider the Machine Learning process as a trial and error experiment. After testing several approaches and methods We could find a workable model. It was a difficult & challenging process, and ultimately worth the while when the user said, they expected something similar!